BBC Radio 5 live’s award winning gaming podcast, discussing the world of video games and games culture.
…
continue reading
Nội dung được cung cấp bởi LessWrong. Tất cả nội dung podcast bao gồm các tập, đồ họa và mô tả podcast đều được LessWrong hoặc đối tác nền tảng podcast của họ tải lên và cung cấp trực tiếp. Nếu bạn cho rằng ai đó đang sử dụng tác phẩm có bản quyền của bạn mà không có sự cho phép của bạn, bạn có thể làm theo quy trình được nêu ở đây https://vi.player.fm/legal.
Tương tự như LessWrong (Curated & Popular)
Android Backstage, a podcast by and for Android developers. Hosted by developers from the Android engineering team, this show covers topics of interest to Android programmers, with in-depth discussions and interviews with engineers on the Android team at Google. Subscribe to Android Developers YouTube → https://goo.gle/AndroidDevs
…
continue reading
Africa-focused technology, digital and innovation ecosystem insight and commentary.
…
continue reading
Show notes are at https://stevelitchfield.com/sshow/chat.html
…
continue reading
The power of Data is undeniable. And unharnessed - it’s nothing but chaos. Making data your ally. Using it to lead with confidence and clarity. Host Jess Carter is solving problems in real-time to reveal what’s possible. Helping communities and people thrive. This is Data Driven Leadership, a show brought to you by Resultant.
…
continue reading
This is the audio podcast version of Troy Hunt's weekly update video published here: https://www.troyhunt.com/tag/weekly-update/
…
continue reading
Redefining AI is the 2024 New York Digital Award winning tech podcast! Discover a whole new take on Artificial Intelligence in joining host Lauren Hawker Zafer, a top voice in Artificial Intelligence on LinkedIn, for insightful chats that unravel the fascinating world of tech innovation, use case exploration and AI knowledge. Dive into candid discussions with accomplished industry experts and established academics. With each episode, you'll expand your grasp of cutting-edge technologies and ...
…
continue reading
We help founders make something people want.
…
continue reading
Flash Forward is a show about possible (and not so possible) future scenarios. What would the warranty on a sex robot look like? How would diplomacy work if we couldn’t lie? Could there ever be a fecal transplant black market? (Complicated, it wouldn’t, and yes, respectively, in case you’re curious.) Hosted and produced by award winning science journalist Rose Eveleth, each episode combines audio drama and journalism to go deep on potential tomorrows, and uncovers what those futures might re ...
…
continue reading
Talk Python to Me is a weekly podcast hosted by developer and entrepreneur Michael Kennedy. We dive deep into the popular packages and software developers, data scientists, and incredible hobbyists doing amazing things with Python. If you're new to Python, you'll quickly learn the ins and outs of the community by hearing from the leaders. And if you've been Pythoning for years, you'll learn about your favorite packages and the hot new ones coming out of open source.
…
continue reading
Player FM - Ứng dụng Podcast
Chuyển sang chế độ ngoại tuyến với ứng dụng Player FM !
Chuyển sang chế độ ngoại tuyến với ứng dụng Player FM !

))
“o1: A Technical Primer” by Jesse Hoogland
Manage episode 454951409 series 3364760
Nội dung được cung cấp bởi LessWrong. Tất cả nội dung podcast bao gồm các tập, đồ họa và mô tả podcast đều được LessWrong hoặc đối tác nền tảng podcast của họ tải lên và cung cấp trực tiếp. Nếu bạn cho rằng ai đó đang sử dụng tác phẩm có bản quyền của bạn mà không có sự cho phép của bạn, bạn có thể làm theo quy trình được nêu ở đây https://vi.player.fm/legal.
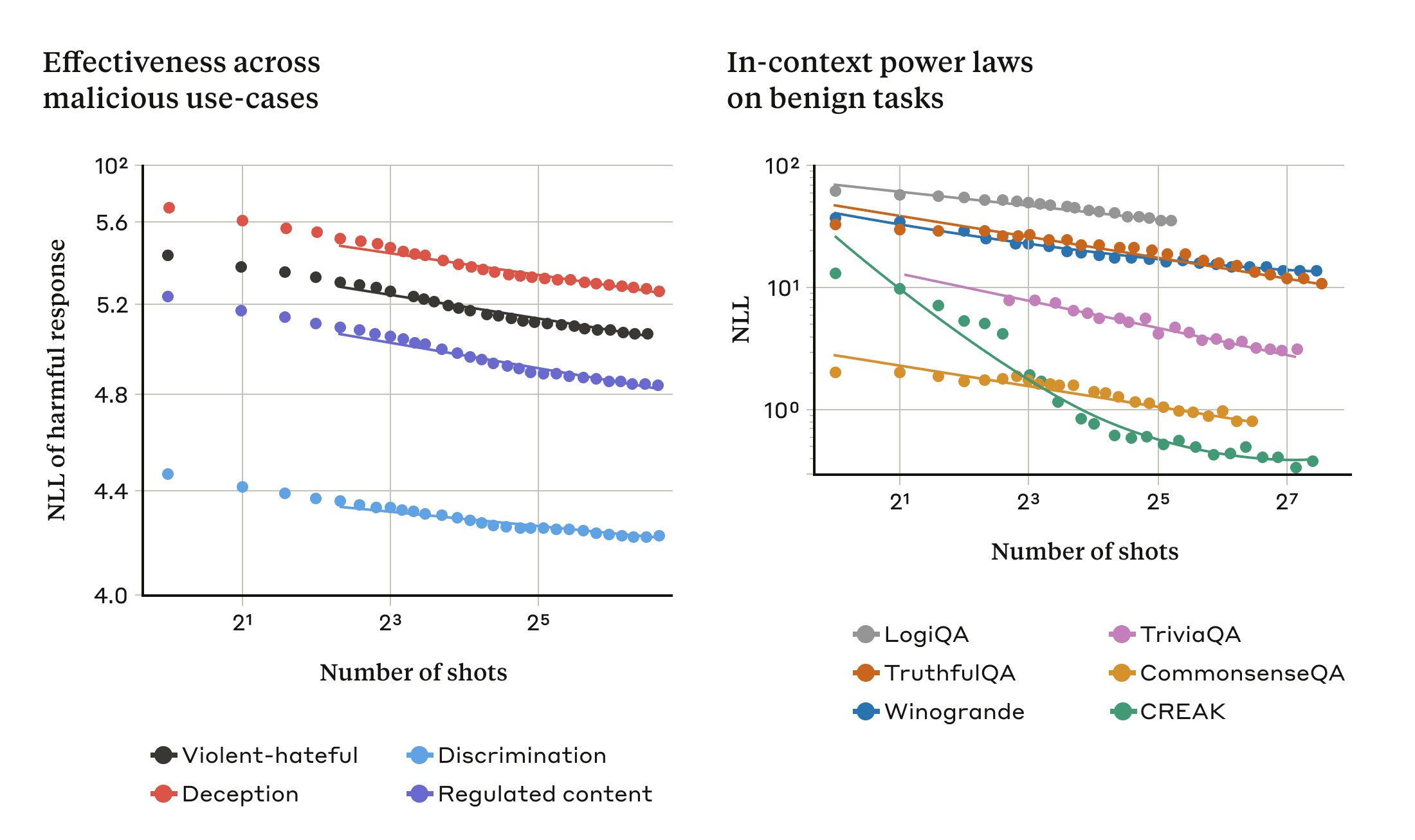
TL;DR: In September 2024, OpenAI released o1, its first "reasoning model". This model exhibits remarkable test-time scaling laws, which complete a missing piece of the Bitter Lesson and open up a new axis for scaling compute. Following Rush and Ritter (2024) and Brown (2024a, 2024b), I explore four hypotheses for how o1 works and discuss some implications for future scaling and recursive self-improvement.
The Bitter Lesson(s)
The Bitter Lesson is that "general methods that leverage computation are ultimately the most effective, and by a large margin." After a decade of scaling pretraining, it's easy to forget this lesson is not just about learning; it's also about search.
OpenAI didn't forget. Their new "reasoning model" o1 has figured out how to scale search during inference time. This does not use explicit search algorithms. Instead, o1 is trained via RL to get better at implicit search via chain of thought [...]
---
Outline:
(00:40) The Bitter Lesson(s)
(01:56) What we know about o1
(02:09) What OpenAI has told us
(03:26) What OpenAI has showed us
(04:29) Proto-o1: Chain of Thought
(04:41) In-Context Learning
(05:14) Thinking Step-by-Step
(06:02) Majority Vote
(06:47) o1: Four Hypotheses
(08:57) 1. Filter: Guess + Check
(09:50) 2. Evaluation: Process Rewards
(11:29) 3. Guidance: Search / AlphaZero
(13:00) 4. Combination: Learning to Correct
(14:23) Post-o1: (Recursive) Self-Improvement
(16:43) Outlook
---
First published:
December 9th, 2024
Source:
https://www.lesswrong.com/posts/byNYzsfFmb2TpYFPW/o1-a-technical-primer
---
Narrated by TYPE III AUDIO.
---
…
continue reading
The Bitter Lesson(s)
The Bitter Lesson is that "general methods that leverage computation are ultimately the most effective, and by a large margin." After a decade of scaling pretraining, it's easy to forget this lesson is not just about learning; it's also about search.
OpenAI didn't forget. Their new "reasoning model" o1 has figured out how to scale search during inference time. This does not use explicit search algorithms. Instead, o1 is trained via RL to get better at implicit search via chain of thought [...]
---
Outline:
(00:40) The Bitter Lesson(s)
(01:56) What we know about o1
(02:09) What OpenAI has told us
(03:26) What OpenAI has showed us
(04:29) Proto-o1: Chain of Thought
(04:41) In-Context Learning
(05:14) Thinking Step-by-Step
(06:02) Majority Vote
(06:47) o1: Four Hypotheses
(08:57) 1. Filter: Guess + Check
(09:50) 2. Evaluation: Process Rewards
(11:29) 3. Guidance: Search / AlphaZero
(13:00) 4. Combination: Learning to Correct
(14:23) Post-o1: (Recursive) Self-Improvement
(16:43) Outlook
---
First published:
December 9th, 2024
Source:
https://www.lesswrong.com/posts/byNYzsfFmb2TpYFPW/o1-a-technical-primer
---
Narrated by TYPE III AUDIO.
---
Images from the article:

 Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.
Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.
Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.502 tập
Manage episode 454951409 series 3364760
Nội dung được cung cấp bởi LessWrong. Tất cả nội dung podcast bao gồm các tập, đồ họa và mô tả podcast đều được LessWrong hoặc đối tác nền tảng podcast của họ tải lên và cung cấp trực tiếp. Nếu bạn cho rằng ai đó đang sử dụng tác phẩm có bản quyền của bạn mà không có sự cho phép của bạn, bạn có thể làm theo quy trình được nêu ở đây https://vi.player.fm/legal.
TL;DR: In September 2024, OpenAI released o1, its first "reasoning model". This model exhibits remarkable test-time scaling laws, which complete a missing piece of the Bitter Lesson and open up a new axis for scaling compute. Following Rush and Ritter (2024) and Brown (2024a, 2024b), I explore four hypotheses for how o1 works and discuss some implications for future scaling and recursive self-improvement.
The Bitter Lesson(s)
The Bitter Lesson is that "general methods that leverage computation are ultimately the most effective, and by a large margin." After a decade of scaling pretraining, it's easy to forget this lesson is not just about learning; it's also about search.
OpenAI didn't forget. Their new "reasoning model" o1 has figured out how to scale search during inference time. This does not use explicit search algorithms. Instead, o1 is trained via RL to get better at implicit search via chain of thought [...]
---
Outline:
(00:40) The Bitter Lesson(s)
(01:56) What we know about o1
(02:09) What OpenAI has told us
(03:26) What OpenAI has showed us
(04:29) Proto-o1: Chain of Thought
(04:41) In-Context Learning
(05:14) Thinking Step-by-Step
(06:02) Majority Vote
(06:47) o1: Four Hypotheses
(08:57) 1. Filter: Guess + Check
(09:50) 2. Evaluation: Process Rewards
(11:29) 3. Guidance: Search / AlphaZero
(13:00) 4. Combination: Learning to Correct
(14:23) Post-o1: (Recursive) Self-Improvement
(16:43) Outlook
---
First published:
December 9th, 2024
Source:
https://www.lesswrong.com/posts/byNYzsfFmb2TpYFPW/o1-a-technical-primer
---
Narrated by TYPE III AUDIO.
---
…
continue reading
The Bitter Lesson(s)
The Bitter Lesson is that "general methods that leverage computation are ultimately the most effective, and by a large margin." After a decade of scaling pretraining, it's easy to forget this lesson is not just about learning; it's also about search.
OpenAI didn't forget. Their new "reasoning model" o1 has figured out how to scale search during inference time. This does not use explicit search algorithms. Instead, o1 is trained via RL to get better at implicit search via chain of thought [...]
---
Outline:
(00:40) The Bitter Lesson(s)
(01:56) What we know about o1
(02:09) What OpenAI has told us
(03:26) What OpenAI has showed us
(04:29) Proto-o1: Chain of Thought
(04:41) In-Context Learning
(05:14) Thinking Step-by-Step
(06:02) Majority Vote
(06:47) o1: Four Hypotheses
(08:57) 1. Filter: Guess + Check
(09:50) 2. Evaluation: Process Rewards
(11:29) 3. Guidance: Search / AlphaZero
(13:00) 4. Combination: Learning to Correct
(14:23) Post-o1: (Recursive) Self-Improvement
(16:43) Outlook
---
First published:
December 9th, 2024
Source:
https://www.lesswrong.com/posts/byNYzsfFmb2TpYFPW/o1-a-technical-primer
---
Narrated by TYPE III AUDIO.
---
Images from the article:
Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.
Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.502 tập
Tất cả các tập
×Chào mừng bạn đến với Player FM!
Player FM đang quét trang web để tìm các podcast chất lượng cao cho bạn thưởng thức ngay bây giờ. Đây là ứng dụng podcast tốt nhất và hoạt động trên Android, iPhone và web. Đăng ký để đồng bộ các theo dõi trên tất cả thiết bị.
Tương tự như LessWrong (Curated & Popular)
BBC Radio 5 live’s award winning gaming podcast, discussing the world of video games and games culture.
…
continue reading
Android Backstage, a podcast by and for Android developers. Hosted by developers from the Android engineering team, this show covers topics of interest to Android programmers, with in-depth discussions and interviews with engineers on the Android team at Google. Subscribe to Android Developers YouTube → https://goo.gle/AndroidDevs
…
continue reading
Africa-focused technology, digital and innovation ecosystem insight and commentary.
…
continue reading
Show notes are at https://stevelitchfield.com/sshow/chat.html
…
continue reading
The power of Data is undeniable. And unharnessed - it’s nothing but chaos. Making data your ally. Using it to lead with confidence and clarity. Host Jess Carter is solving problems in real-time to reveal what’s possible. Helping communities and people thrive. This is Data Driven Leadership, a show brought to you by Resultant.
…
continue reading
This is the audio podcast version of Troy Hunt's weekly update video published here: https://www.troyhunt.com/tag/weekly-update/
…
continue reading
Redefining AI is the 2024 New York Digital Award winning tech podcast! Discover a whole new take on Artificial Intelligence in joining host Lauren Hawker Zafer, a top voice in Artificial Intelligence on LinkedIn, for insightful chats that unravel the fascinating world of tech innovation, use case exploration and AI knowledge. Dive into candid discussions with accomplished industry experts and established academics. With each episode, you'll expand your grasp of cutting-edge technologies and ...
…
continue reading
We help founders make something people want.
…
continue reading
Flash Forward is a show about possible (and not so possible) future scenarios. What would the warranty on a sex robot look like? How would diplomacy work if we couldn’t lie? Could there ever be a fecal transplant black market? (Complicated, it wouldn’t, and yes, respectively, in case you’re curious.) Hosted and produced by award winning science journalist Rose Eveleth, each episode combines audio drama and journalism to go deep on potential tomorrows, and uncovers what those futures might re ...
…
continue reading
Talk Python to Me is a weekly podcast hosted by developer and entrepreneur Michael Kennedy. We dive deep into the popular packages and software developers, data scientists, and incredible hobbyists doing amazing things with Python. If you're new to Python, you'll quickly learn the ins and outs of the community by hearing from the leaders. And if you've been Pythoning for years, you'll learn about your favorite packages and the hot new ones coming out of open source.
…
continue reading
Player FM - Ứng dụng Podcast
Chuyển sang chế độ ngoại tuyến với ứng dụng Player FM !
Chuyển sang chế độ ngoại tuyến với ứng dụng Player FM !



